Inside System Initiative’s Messaging Architecture
By Nick Gerace
10/21/2025
From the moment you remove a user from all your services to the final review screen summarizing the hundreds of resources deleted, all of System Initiative’s (SI) backend services have communicated through a single service: NATS. This post dives into the how, what, and why behind NATS, the core of our distributed system architecture.
Rising to the Occasion
Originally, NATS made its way into System Initiative by my dear friend Fletcher in order to address problems solved by fan-out messaging, such as publishing WebSocket events to the front end application. Steadily, NATS grew into a bedrock service for inter-service communication. The process happened naturally.
- “How do we communicate between the API server and the job dispatch service?”
- “I need to compress a set of rapid requests into a single, compressed request at the server-level with guaranteed ordering.”
- “I need to scale out horizontally, and the first reader has access to requests on this Change Set.”
- “How do we version messages for rolling deployments in case the request payload needs to be deserialized as the old version on the other side?”
Both core NATS and its durable queuing service, NATS JetStream, became both the networking and messaging lifeblood of the stack. Rather than communicating through Kubernetes custom resource definitions, sending loads of http requests, or handling gRPC calls, NATS provides a layer for three major architectural requirements at once:
- Fan-out, distributed messaging
- Durable queuing with replication and guaranteed ordering
- Key-value storage
Whether you are using Claude Code, our Python and TypeScript SDKs, or our web application in a multiplayer setting, System Initiative must handle multiple, concurrent workloads and resolve the end-user’s intent —while also supporting multiple tenants and rolling deployments. The ability to rely on both fan-out messages and durable, ordered queues allows us to do just that.
Show Me The Guts!
Let’s stop yapping for a second and examine how a change to your workspace flows throughout System Initiative. I’m an engineer. If I were reading this blog post, I’d want to see the gory server closet over the pristine slide deck, so… dense diagram incoming!
Before that, here is a summarized overview of the flow:
- Make a request to our API servers via our MCP server, public API, Python or TypeScript SDKs, or the web application.
- The relevant API server, “sdf” or “luminork”, will perform business logic work based on user desire and intent. The server will conditionally offload work to our job processing service, “pinga”, and function execution service, “veritech”, as needed.
- The finalizer service, the “rebaser”, will stamp/finalize changes made to the workspace after all prior work is completed successfully.
- The materialized view generation and post-processing services, “edda” and “forklift”, respectively, will do their work based on the finalized changes.
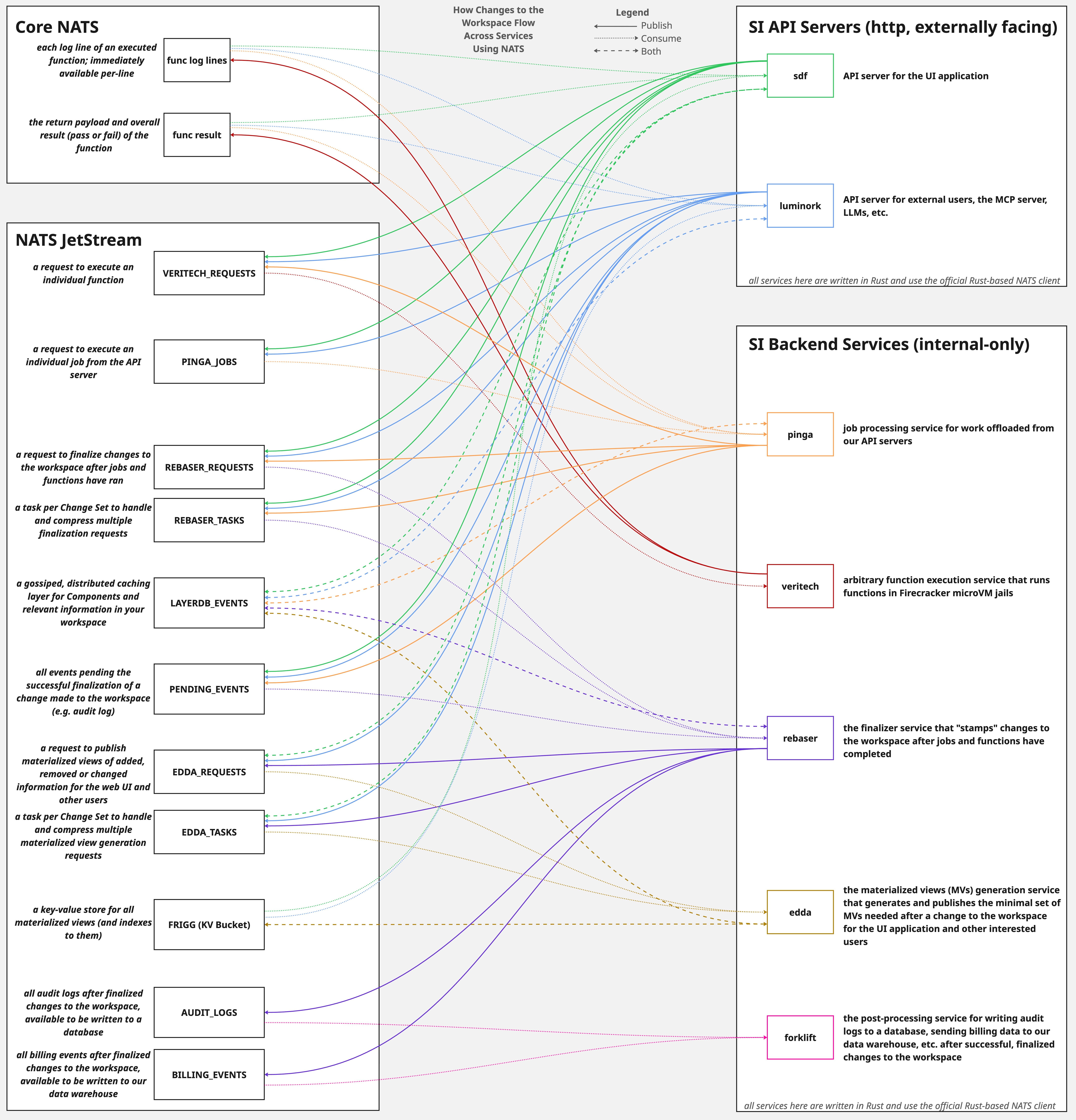
Ah. Messaging in all its glory, but it can be a beast without an example. The following example does not include every NATS-related event that happens, but draws a throughline through the above diagram. When you create an “AWS::EC2::Instance” Component using our MCP server while looking at the web application in another window, the following happens:
- Our MCP server makes an http request to the “luminork” API server to create a component.
- Setting all the default values, automatic subscriptions, and desired values passed into the create request requires the job dispatch service, “pinga”. “luminork” will publish a request to the
PINGA_JOBSstream for all that work to get done. If successful, it will return a 200 OK status code with its response to the MCP server client call. - In “pinga”, all complex or user-authored functions that need to run will be published to the
VERITECH_REQUESTSstream. - In “veritech”, all functions from the requests stream will be executed in parallel, up to a concurrency limit, and will return the logs and results to the original requester. In this case, that’s “pinga”.
- In both “pinga” and “luminork”, once all operations and functions are complete, they will publish to the
REBASER_REQUESTSstream, allowing the work to be finalized to the Change Set. - In “rebaser”, all requests to finalize work in the Change Set are serialized, compressed (if possible), and processed accordingly. The immutable snapshot of the workspace is saved to a database.
- The “rebaser” publishes a message to the
EDDA_REQUESTSstream, allowing us to build the minimal set of materialized views for the web application. - In “edda”, all requests to generate materialized views are serialized, compressed (if possible), and processed accordingly. We generate the materialized views based on all relevant information added, changed, and removed within your Change Set.
- In the web application, patches published by “edda” result in real-time, up-to-date changes to what you see, with multiplayer and multi-tab/window guarantees.
The Value
From the earliest implementations of System Initiative, two commitments have endured: multiplayer editing and real-time updates. Many SI backend services are written like UNIX applications: they do one thing and they do it well. They are scoped with specific database access. They are scoped to specific library calls. They are scoped to their domains of expertise. When a domain-driven distributed architecture only needs the minimal amount of information in a request to be successful, you can leverage high throughput, lightweight messaging for obscenely fast performance across multiple tenants. The door is also open for both horizontal and vertical scalability, given the ability to subscribe to subjects and consume from streams with fine-tuned customization.
NATS provides our backend services the ability to “talk” without the added headache of server messaging consensus, dropped message handling, and custom re-delivery architecture. We have not needed to build bloated custom resource definitions for a complex and brittle set of Kubernetes operators.
The 3-in-1 benefits of fan-out messaging, durable, ordered queueing, and a key-value store are the bang-for-buck package that has helped make discovering an entire fleet of AWS EC2 Instances and VPCs expedient and accurate in SI.
Closing
System Initiative’s usage of NATS is ever-evolving, and we have more challenges ahead. How do we handle our next frontier of scalability challenges? How do we process messages on a dead-letter queue to be re-delivered at a much later point? What tunables do we need to adjust for replication, stream configuration, and NATS client management within our servers? The questions are endless, but what we do know is this: NATS’s mix of ephemeral and durable messaging, combined with its class-leading throughput performance, is a bedrock to our stack.
AI Native Infrastructure Automation enables you to set up an entire VPC with virtual machines running non-trivial workloads in minutes, not days. That outcome would not have been possible without our engineering team’s investment in the messaging architecture. Thus, the engineering team at SI continues to utilize NATS in its domain-driven architecture to actualize that outcome, and we’re just getting started.

Nick Gerace, Software Engineer
Nick’s career is defined by an unyielding pursuit of the future of infrastructure software. That vision finds its realization through his engineering work at System Initiative.